 BBQ-Cloud
BBQ-CloudMy Homelab for 2024 Part 2
The Kubernetes cluster, where a bunch of services lives…
1.26 was the best logo ever right…
The fundation
The cluster consists of 6 Virtual Machines running on the Proxmox Cluster:
- 3 Control Plane node with 2 Cores and 6G of RAM
- 3 Worker node with 6 Cores and 20G of RAM
At the time I’m writing this, they are running Debian 11 as OS and Kubernetes 1.28. I will update them to Debian 12 as I already started migrating some machines to 12 and the Hypervisor are already on 12. But for Kubernetes I like to stay one version behind, as they support the 3 last version, there is no problem doing this.
The cluster is provisionned and updated via the Kubeadm tool, I wanted to learn the Kubernetes “Vanilla” tool, then I found it quite simple so I ditched to idea to switch to K3S… even this product is quite cool too !
It is in HA Mode with Etcd as backend, CoreDNS for the cluster DNS and I use kube-vip in ARP mode to share a Virtual IP between my control plane nodes. I can always access the API is one node still up !
I use Calico as my CNI ( Networking ) plugin, deployed with the Calico Operator, but I want to try Cillium
Each proxmox host one worker and one control plane node.
Storage
Longhorn
I wanted to have shared storage between my nodes, but not by using my NAS as a single point of failure. So I use my NAS to access data on it via NFS Mounts for Musics and Media that are not used by critical workloads, but for things that I do not want off when my NAS is in maintenance, I use Rancher Longhorn. As my workers are connected through their own bridge with 10G, longhorn is taking advantage of the faster network.
Longhorn data are on a dedicated disk on the VM, this disk is on the nvme storage of the proxmox. I can case longhorn fill up the disk, the workload using longhorn will crash but the kube node will not…
Local volumes
I also use local volumes for some workloads when I prefer to manage the availability directly with the product… The most common use case I have for that is Postgres Databases. I do not need to have replicated storage as the replication is managed by the database itself… I also use this for Prometheus metrics for example because my Prometheus is in HA Mode too, more on this later !
This is the storage class I use for that :
|
|
And if I want a volume :
|
|
LoadBalancer
To deploy Loadbalancer type service I use Metallb in ARP mode. My services are tied to a virtual IP and Metallb will manage that VIP to make it follow the service when the pods are moving. The downside of this mode is that all traffic is routed to one node, so it can not be considered as true loadbalancing, but for failover it works like a charm !
Ingress Controller
The Ingress controller of that cluster is Traefik because when I started to learn docker and swarm I found it perfect, so I tried it on kube and found the same level of happyness with it ^^. I use the Custom Ressources Definitions from Traefik but the “regular” ingress api object is also enabled so that other software can leverage traefik like helm, operators or cert-manager.
I also use it as my reverse proxy for non-kubernetes workload. My NAS, Hypervisor WebUI, PBS WebUI are also served by traefik. To do this I use external service defined “by hand”.
Here is the proxmox webUI example which use 3 servers for backend :
|
|
Then the “normal” Traefik IngressRoute to use it :
|
|
Addons
There is some Addons that I think are really usefull in a Kube cluster.
Kube metric server
The Kube Metrics Server is here to give you basic metrics on your cluster, it is needed for the top commands to works like so :
|
|
But this is also what you need for Horizontal and Verticial Pod Autoscaler to work ! This is less true now because I’m pretty sure that I saw you can connecter thoses autoscaler to custom metrics providers.
Sealed Secrets
SealedSecrets is mandatory if you want to go full GitOps like me, it will allow you to push secrets to a git repo, even a public one, because your secrets become encrypted and only your kubernetes cluster can decrypt them ! It works like this :
- You create a “regular” kubernetes secret in mysecret-unsealed.yaml
- You encrypt that secret with
kubeseal -f mysecret-unsealed.yaml -w mysecret.yaml - It will output a file to mysecret.yaml
kubectl apply -f mysecret.yaml- The kubeseal controller will see the sealedsecrets object in your cluster and will unencrypt it to a regular secret that you can use like any other k8s secret !
- You can ditch the unsealed file if you want, in any case that file should NOT be commit to a git repo ! The sealed one is made for that !
I use it for every secrets, all my secrets are commited to a git repo, I also use a .gitignore with a pattern in case I forgot unsealed files somewhere…
Kured
Kured is as Good as simple… It watches your nodes ( deployed as a DaemonSet ) for a specific file and reboot them when that file is present. So as I have debian with automatic upgrades configured, it will reboot the node when new kernels are installed for exemple. You can configure a lot of things like :
- Planning, when nodes are allowed or not to reboot
- Where to send notification on reboot, I use teams
- Only drain pods that match a label
- A Prometheus instance to abort reboot if alerts are found
- Max nodes to reboot at the sametime …
Defrag Cron Jobs
I use to have regular warnings of my Etcd Database being fragmented so I created a cronjob to take care of this and never had anymore alerts :
|
|
Cert Manager
Cert-manager allows you to request / issue certificates automatically. Several projects use it so I guess everyone needs it in a cluster at some point. Unless you manage certs yourself. I also use it to request HTTPS Certs for Traefik… I use the HTTP challenge with Let's Encrypt.
Compliance checker
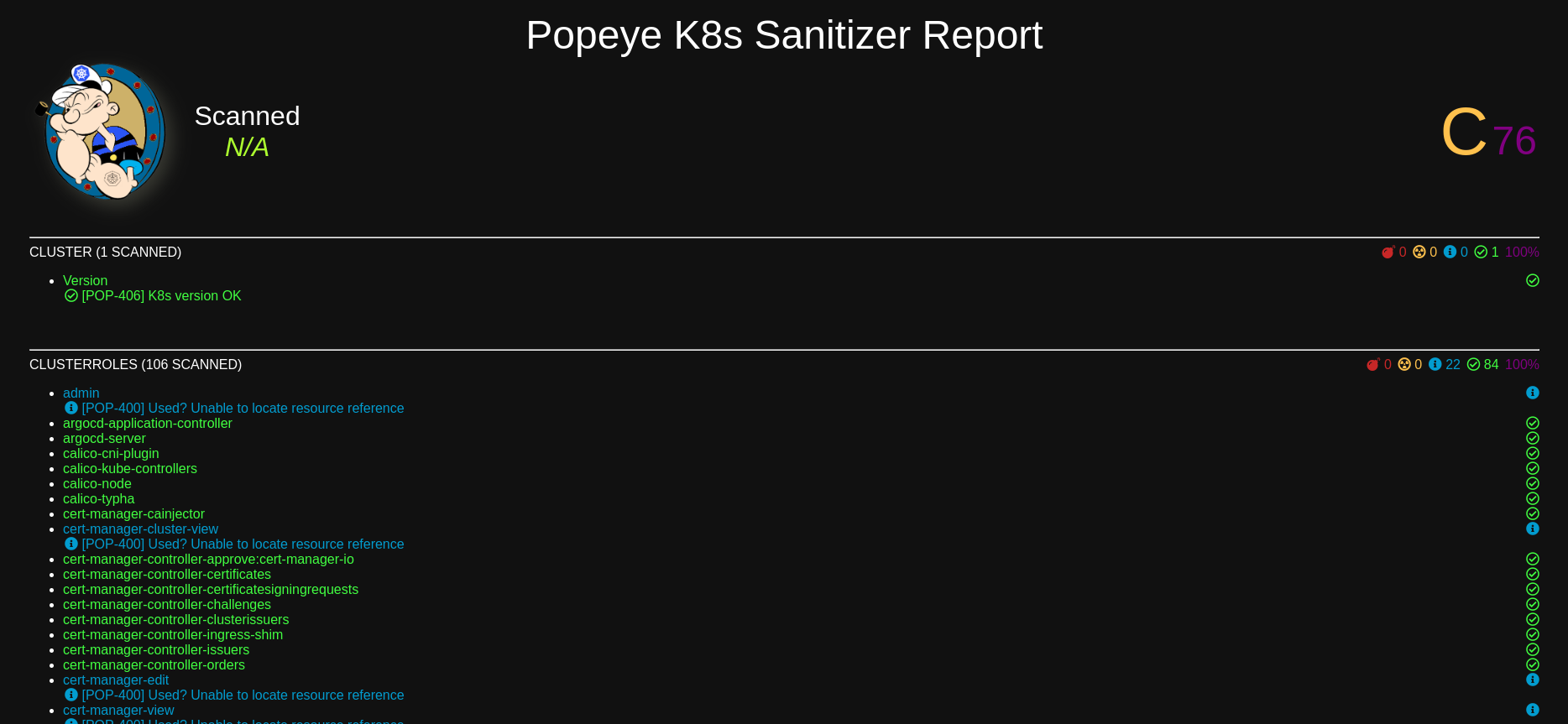
I found this little tool called Popeye than can scan a cluster and tell you where you made some not so best practices things. There is an option to output in HTML format… So I use it directly in cluster, as a CronJob, and expose the result with a Caddy Web server pod. This way I can check the compliance of my cluster with a web browser.
Diun Image checker
Diun will watch your cluster and send alerts when new version of Images you are using got a update. As I’m running full GitOps I will switch this to Renovate but this little cool tool is worth mentionning !
Next part will be the supporting services running on that cluster